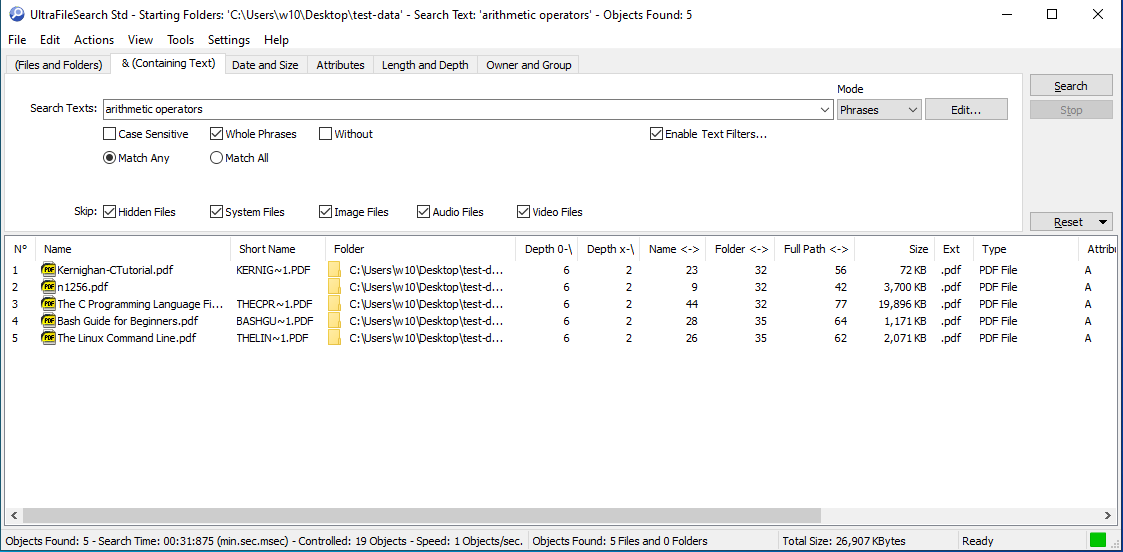
Having the ability to search the content of files is important, it provides a better workflow, and more productivity.
This is a rundown of the best software, which allows files content to be searched, as in for example, searching for the occurrence of a phrase, or of a word, in let us say a PDF or an EPUB file. This is also known as performing full text search.
Table of Contents
Regain
This is a free software which is based on Apache Lucene. Apache Lucene is used for document indexing. Regain is not limited for searching file contents, but it can additionally index websites. It has been a while since the software has been updated, the last stable version dates to 2014.
Regain requires java to be installed, and once this is done, you just have to extract the downloaded regain archive, and double click on the regain jar file.
Regain search and options settings are web based. Upon starting regain, it will ask for allowing passage through the firewall, and it will also open the default web browser with regain welcome page. Additionally, a small tray icon, is placed on the taskbar, which you can right click on, to get the options of search, status, preferences, and exit.
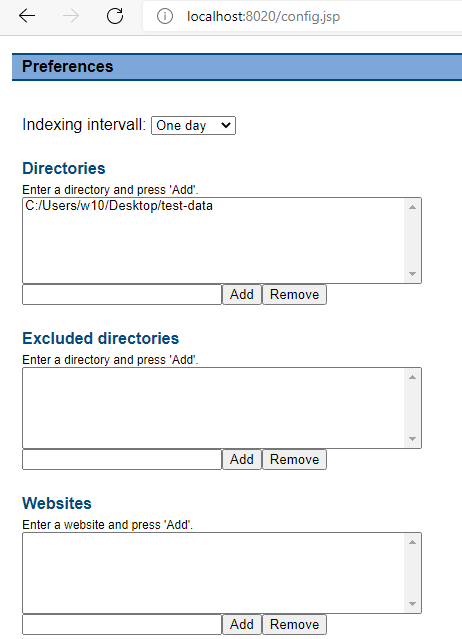
Clicking preferences, you can configure the folder and websites, that you want to index. Additionally, you can configure the indexing interval.
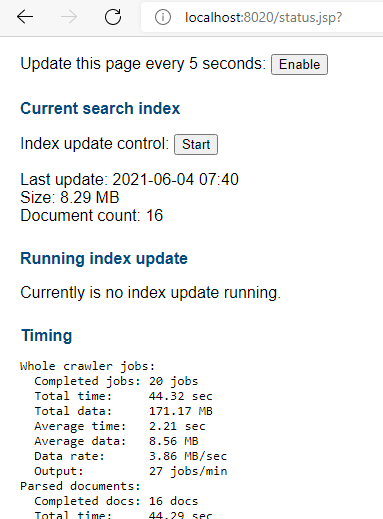
Once you click on save, indexing starts, and you can see its status, by clicking on status.
Indexing does consume memory, but once indexing is done memory usage is acceptable. Indexing a website was a little bit problematic, but it did finally work.
Regain supports indexing html, PDF, open office, Microsoft office, RTF, Xml, and text files. Additionally, it supports using the installed iFilters under Microsoft windows, to parse and index additional files. More information about supported file types, can be found here .
An index has certain fields that can be queried. By default, regain creates the following index fields:
url: The document URL.
path: The navigation path to the document. It cannot be searched.
title: The document’s title.
headlines: The headlines contained in the document.
content: The document contents.
summary: The summary shown in the found result page.
size: the size of the document in bytes. This field cannot be searched.
last-modified: The last modification date of the document. Cannot be searched.
extension: The document file extension.
groups: The groups which are allowed to search the document, if access right management is enabled.
For searching, Lucene query syntax can be used. Documentation about this syntax can be found here .
Basically, you can search for an exact match, by quoting your terms, thus forming a phrase to be searched for. If no quotation is used, then it is as if, searching for separate terms, independent of one another, so it is like using a Boolean OR.
Boolean operators such as AND, OR, NOT can be used. By default, Lucene uses OR. A + operator can also be used, as in +A B C, which means that A must be found, and B or C are optional.
A field to match its content can be specified, as in: content: "content to search" AND extension:pdf , which will search the content field, for the entered phrase, and the document type must be PDF.
The wild cards? and * can be used to match one, or any number of characters, in a single term. For example hell* , will match hello or any word which starts with hell . * and ? cannot appear at the beginning of a word.
For orthographic errors, or for other spellings, or for similar words, the ~ operator can be used. It takes as argument, values between 0 and 1, where 1 means highest similarity. So, for example, roam~ means a similarity of 0.5, hence foam, and roams are a match.
For a phrase, you can also do what is called a proximity search, which is basically how close terms must be one to another. As an example, "hello world"~10, means that hello and word must have at most 10 terms between one another.
Parenthesis can be used to group terms together, as in (A AND B) OR C, or content:(+A B) C, so for the second example, the content field will be searched for A or B , where A is mandatory, and other fields will be searched for C.
Special characters&& || ! ( ) { } [ ] ^ "~ * ? : \ + -, which are part of the query syntax can be escaped by preceding them with a backslash, \ .
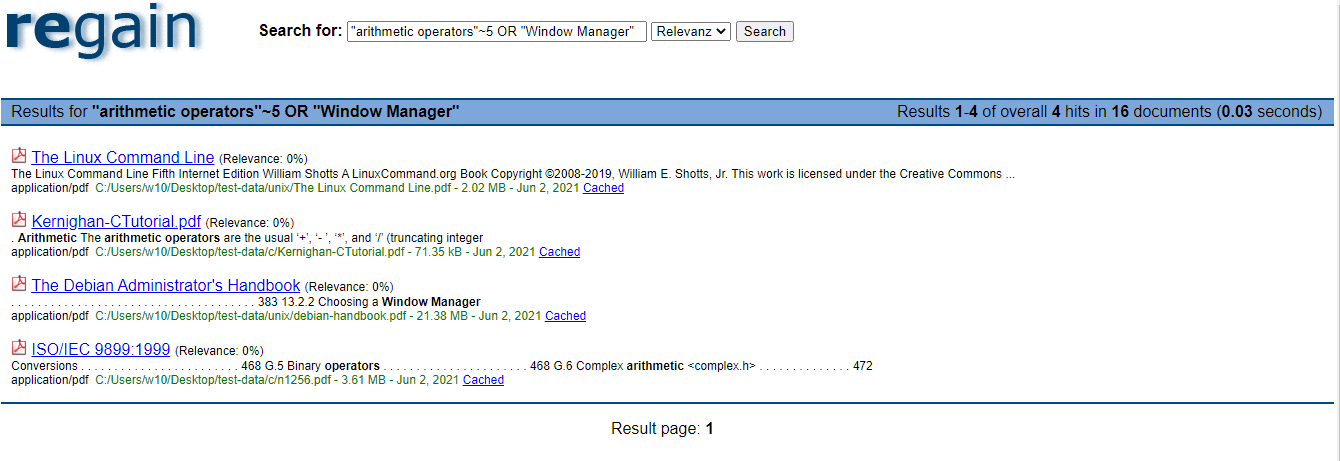
Resulting is not bad, searching is fast, and the results are displayed in a web interface, similar to google, but word highlighting does not always work, and the provided summary, depending on what data is found, is not that great, also where in a document a search term is found is not specified, so no page number or anything similar.
Depending on what you are searching for, it seems that searching for a phrase and using the proximity operator will yield the best results. So, searching for individual terms, might not yield what you are actually searching for.
This one requires java, and it will automatically start downloading and installing java, if a java runtime is not found.
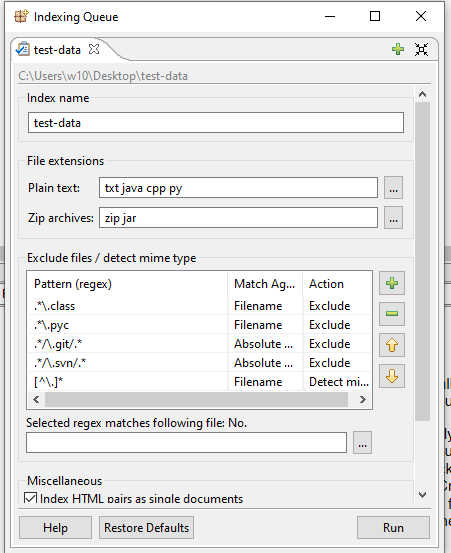
Once docfetcher is installed, it will launch a screen showing some documentation. An index must be created, by clicking on Search Scope, and selecting create index from, and choosing the folder that you want to index, and then clicking on run.
Docfetcher supports indexing PDF, EPUBs, RTF, text, Microsoft office, and Open office documents. Indexing does use memory. For the complete list of supported formats, you can check this link .
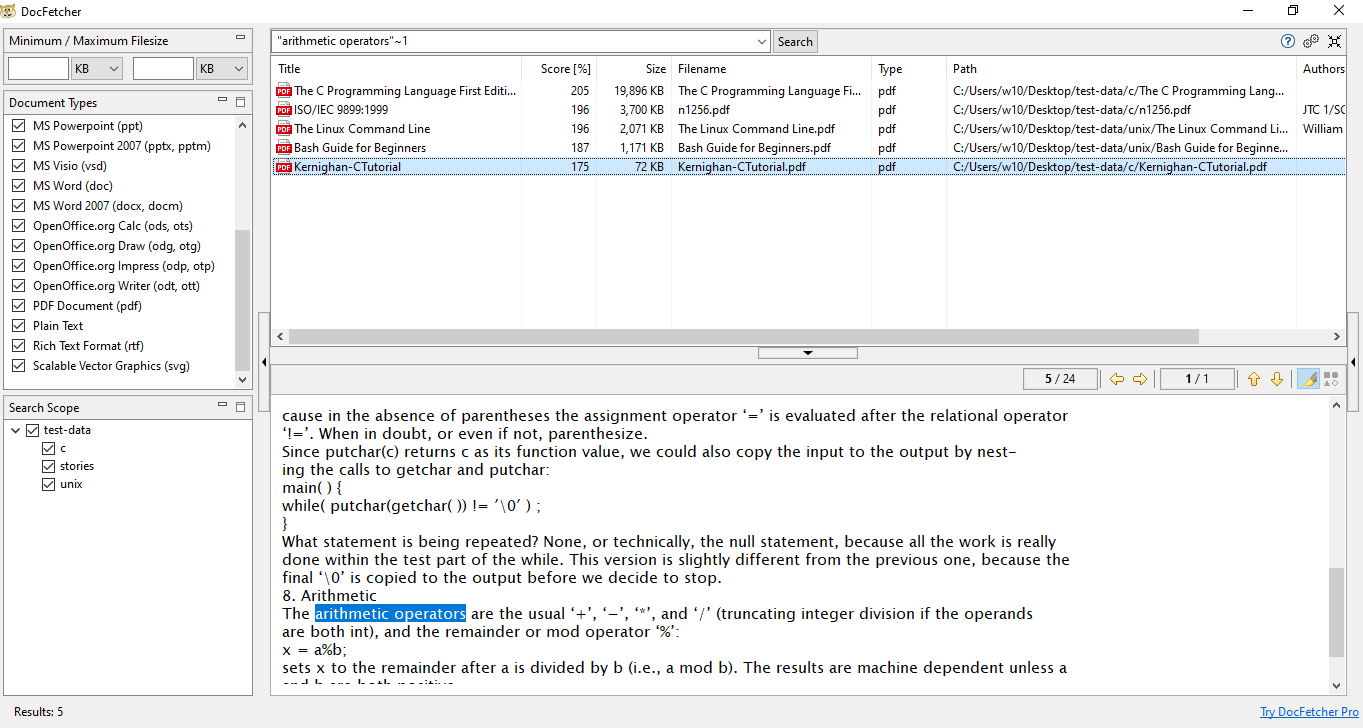
The query syntax is the Lucene query syntax, so it is the same as the one described in regain. In the preview pane, you can browse through the found results. Word highlighting works, so you can pinpoint exactly where in a document your words were found.
Docfetcher offers a pro version, with additional features, such as a bundled java runtime, as not to install java separately, additionally it offers indexing additional file types such as 7-zip, FB2, and MOBI formats. For a full list of the pro features, you can view this page .
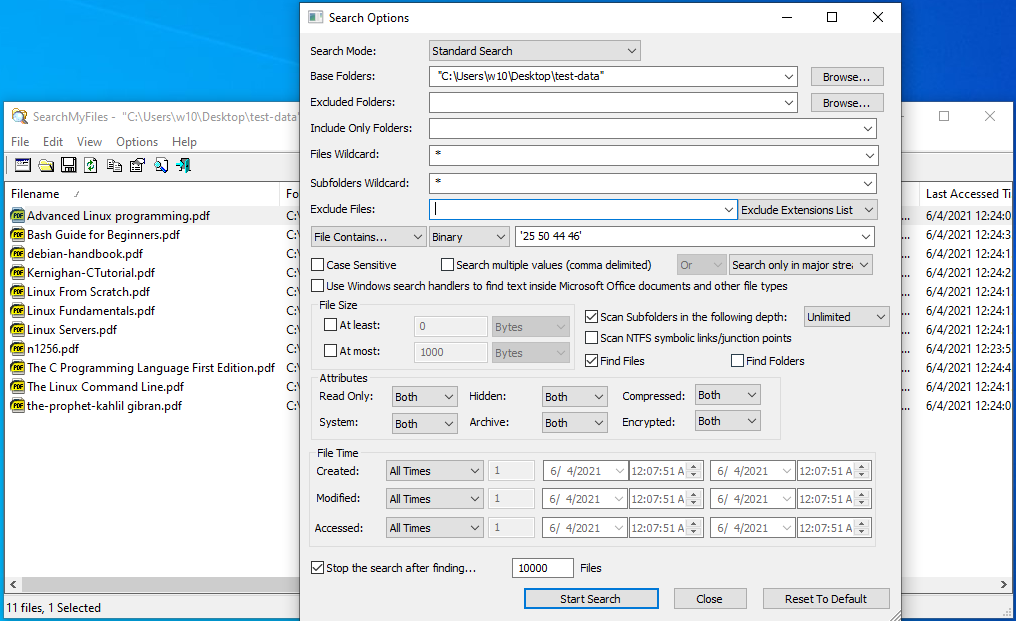
This is a free software, its focus is not searching the content of files, but it provides an option, to search for files, which contain certain textual, or binary data.
To search the binary content, values must be provided in hex, as in '25 50 44 46', which has an ASCII equivalent of %PDF.
The textual content of certain files, is searched by using a feature in Microsoft windows, called iFilter, which allows any entity, to provide mechanisms, for extracting textual content, and properties, from any file type.
By default, search is done, as if the words are quoted, so they should appear in the document, as they appear in the search field, so for example the ordering of the words does matter.
Besides that, by default, search is case insensitive, which you can change to case sensitive.
Multiple search values can be provided, by ticking the multiple values options, and separating the values by a comma. By default, on multiple values, Oring is used, but you can choose ANDing if you want.
Finally, if the wildcard option is used, the content can be searched by using wildcards, such as * to match anything, or ? to match a single character. So, you can use ? as a way to simulate NEAR or proximity search, which is handy to get relevant results under certain conditions.
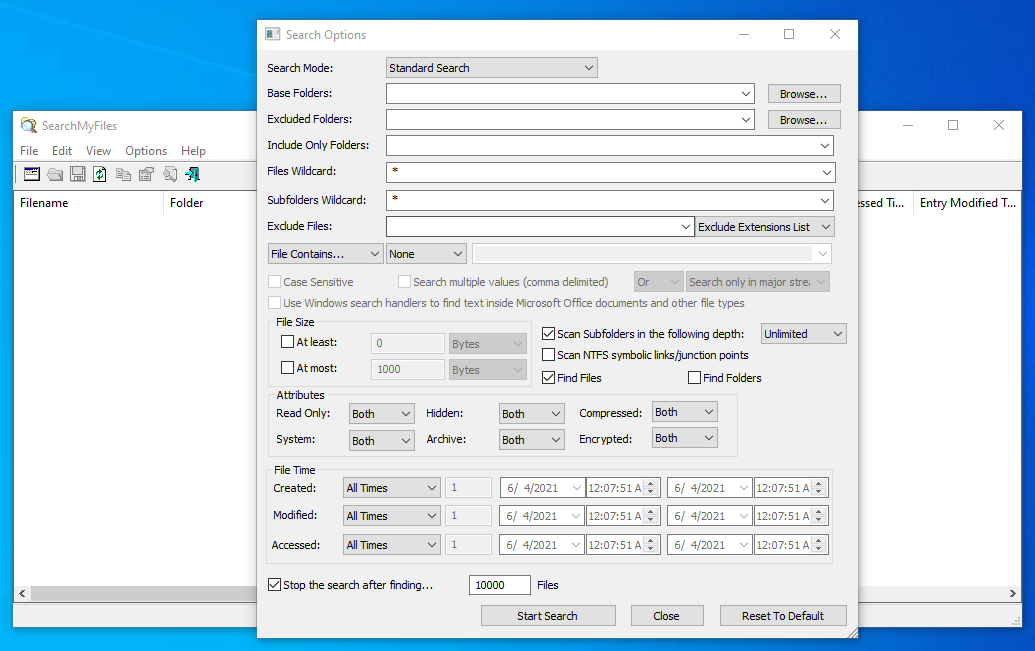
Search speed, and performance are acceptable. other search options can be specified, such as the file size, its modification date, its attributes, the folders that are included, or excluded, file wildcards, as in *.txt;*.pdf to search only pdf and txt files.
The result pane, does not contain a preview, nor does it specify, where in a file, a match was found. The program does not use an index, an index can simply make searching faster.
Both FileLocatorPro and Agent Ransack, are different names, given to the same software, for marketing reasons.
FileLocatorPro has a free version, called the lite version. The lite version is severely limited, for example it does not support some Boolean operators, such as NEAR. It additionally has a pro version. The pro version offers a 30 days trial period. A comparison of the features between the lite and pro version, can be found here .
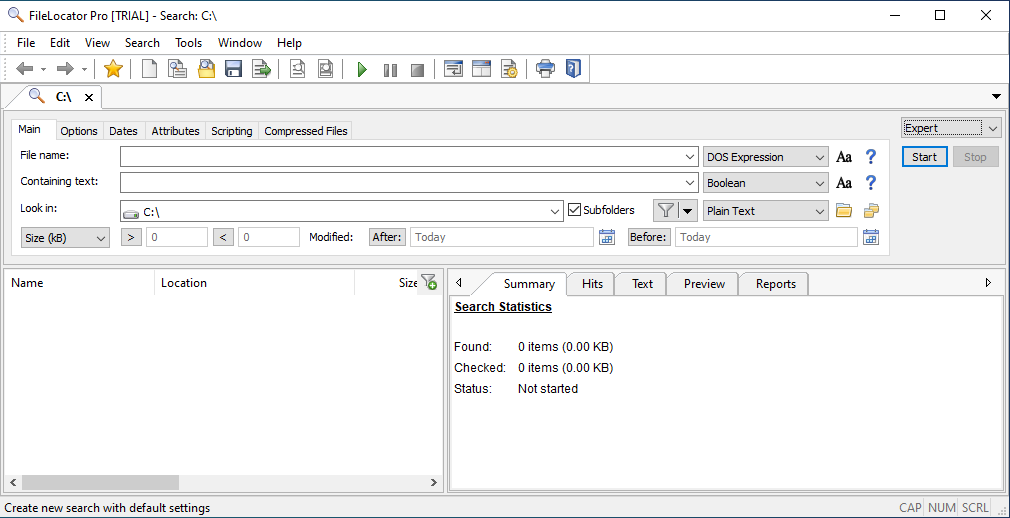
Searching using FileLocatorPro, can be done by selecting one of: Expert, basic, or Index Search.
It supports searching the contents of PowerPoint, excel, word, pdf, EPUB, CHM, and text files. FileLocatorPro also states, that it can search through the content of compressed files, such as zip files, but this option must be selected. The full list of supported files can be found here .
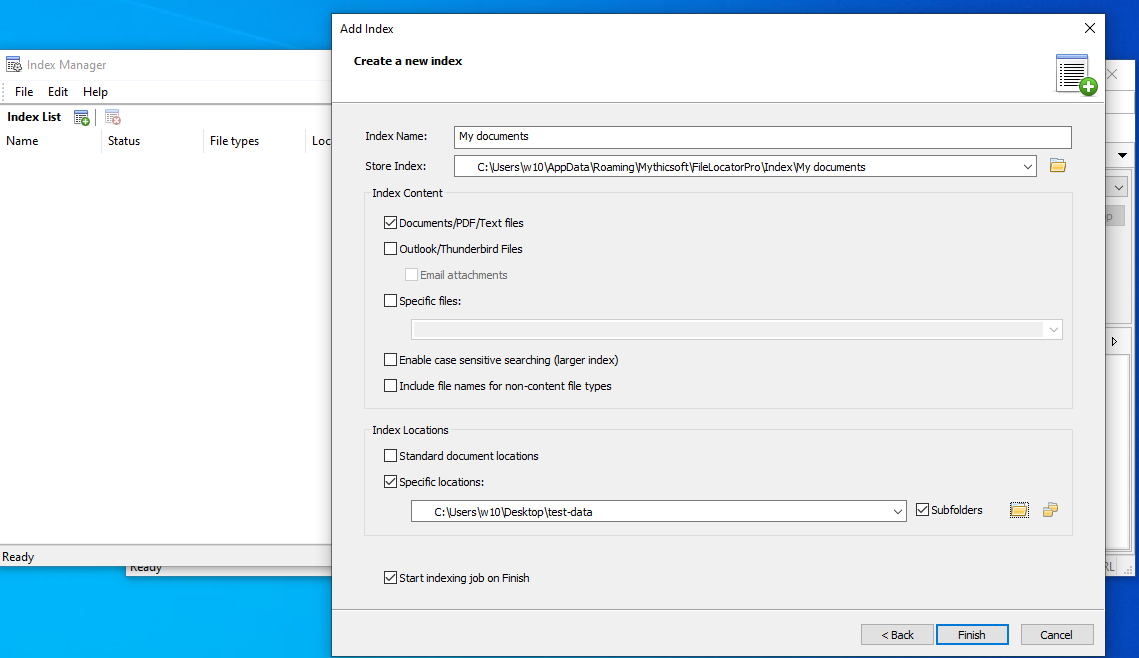
An index is not created or updated, automatically, but you must create and update the index manually. To do so, you must use tools -> Index Manager, and follow the options to create the index, which is providing a name, the kind of data to index, and the locations you wish to index.
When doing expert search, the index is not used, so searching is actually slow.
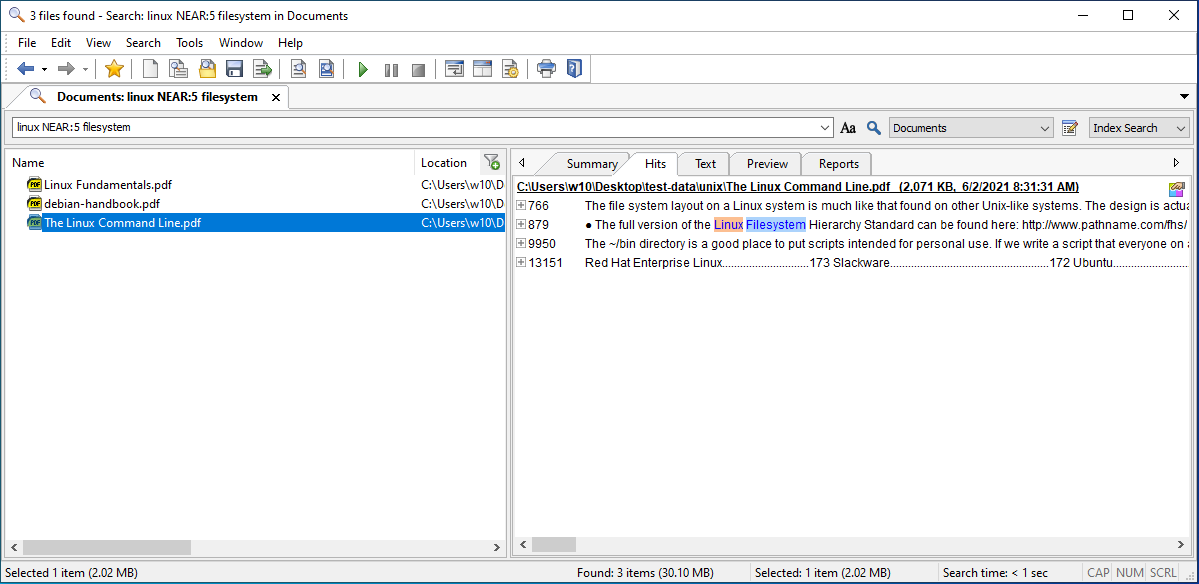
Doing Index Search is fast, and you can use what they call Boolean operators, AND, OR, NOT, NEAR, LIKE. Near actually makes the search more relevant, it is about searching for words within a certain distance, one from another. The distance is measured in number of characters, the default distance is 100 characters between words.
LIKE, is about searching for words, similar to the one provided. Similarity can be configured, for example, should a word which only differ by one character, considered to be similar, or more than one character? The default option is by more than one character.
The found results, and where in the document they appear can be previewed.
Expert searching supports additionally to Boolean operators, searching by using regex, or a combination of Boolean and regex, or fuzzy searching.
Anytxt claims that it is capable of performing full text search of documents under windows, so probably it has some inverted index, which is used to perform the searching, instead of actually searching the document.
Anytxt supports searching the following formats: txt, word, excel, PowerPoint, PDF, e-books such as EPUB or CHM, WPS word, excel and PowerPoint. A full list of supported documents can be found here .
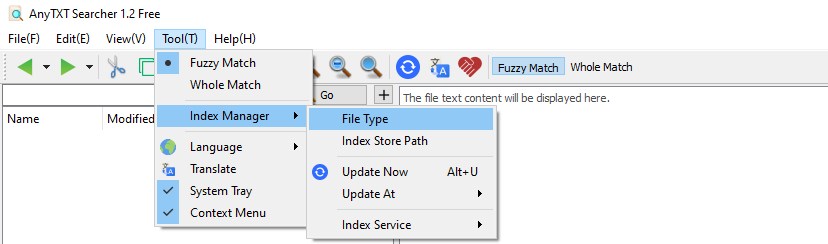
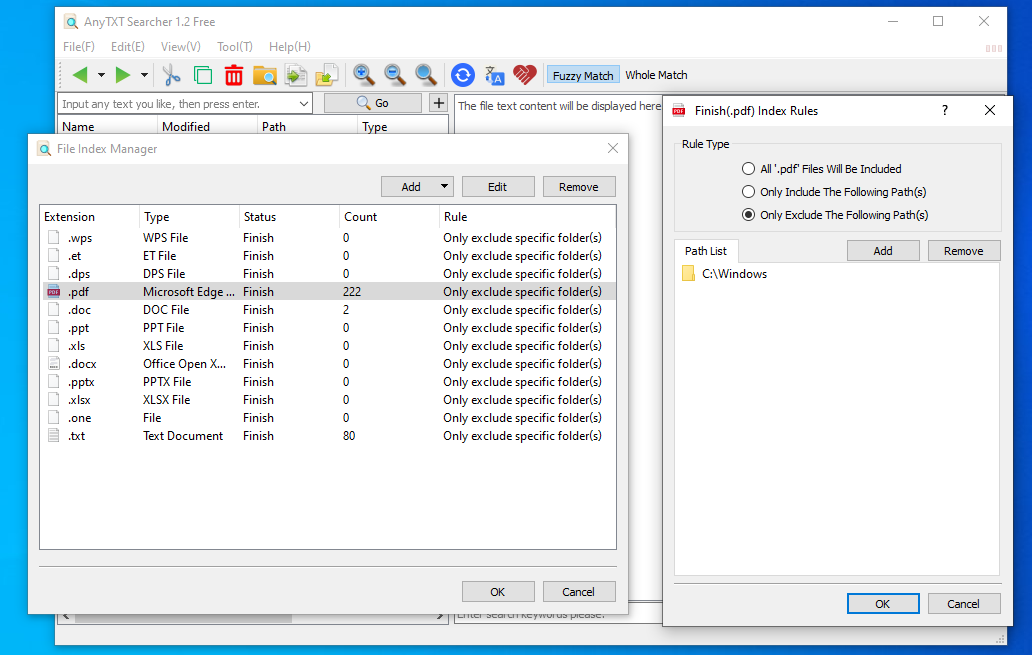
Anytxt does allow selective indexing, of documents or folder, this can be done by going to Tool -> Index Manager -> File Type.
Once there, you can add or remove extensions, and set the paths, that you want to include or exclude by clicking on an extension, and selecting edit. By default, it seems, that EPUB files are not indexed, so you might need to add them manually.
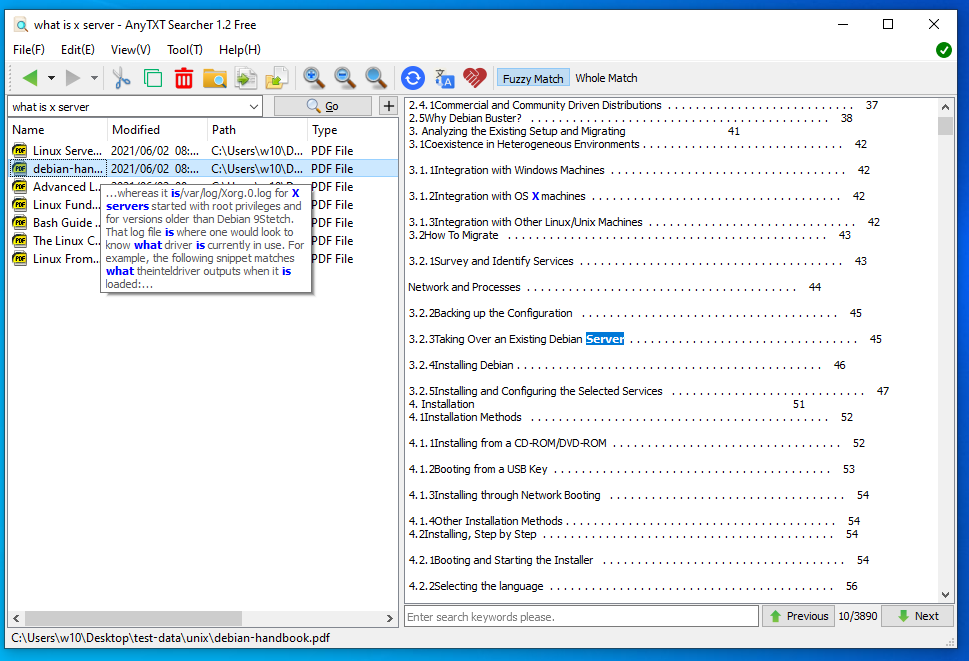
Anytxt does not offer any documentation, but it has a support forum. There are two options to perform searching, either whole match, which seems to be exact matching, which simply means, that the provided search words, should occur as is in the document, or fuzzy word match, which seems to be that the provided words, should occur in the document, without factoring in ordering or proximity.
Searching through the index was fast, and you can preview matches by hovering over the result, or you can open up the document in the right pane, by selecting it.
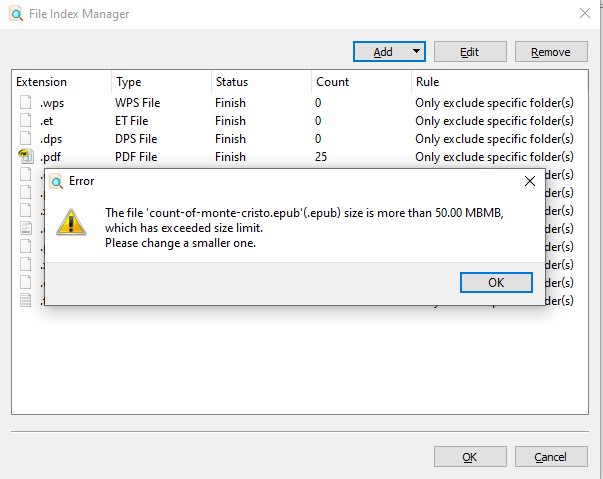
It seems that any text does not support using meta characters, or words such as not, or minus. It does not seem to consume too much CPU or memory, while indexing or searching. AnyTxt cannot perform indexing of files larger than 50MB.
This one is paid, but it offers a 30 days trial period. It works similarly to SearchMyFiles , as such it is not necessary to review it. Search speed, and performance are also acceptable.
Windows search can also be used to search the contents of files, as long as there is an iFilter which is available to provide the textual content to search in.
To set this up, you need to type in Indexing Options, in the search box of the task bar.
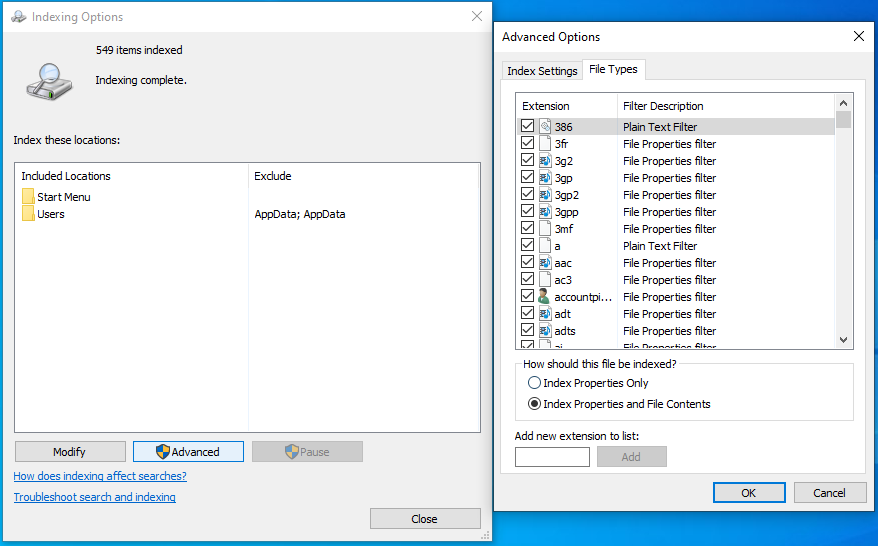
After that, and in the new screen which appears, click on Advanced, next on File Types, and select Index Properties and File Contents, to enable file content indexing.
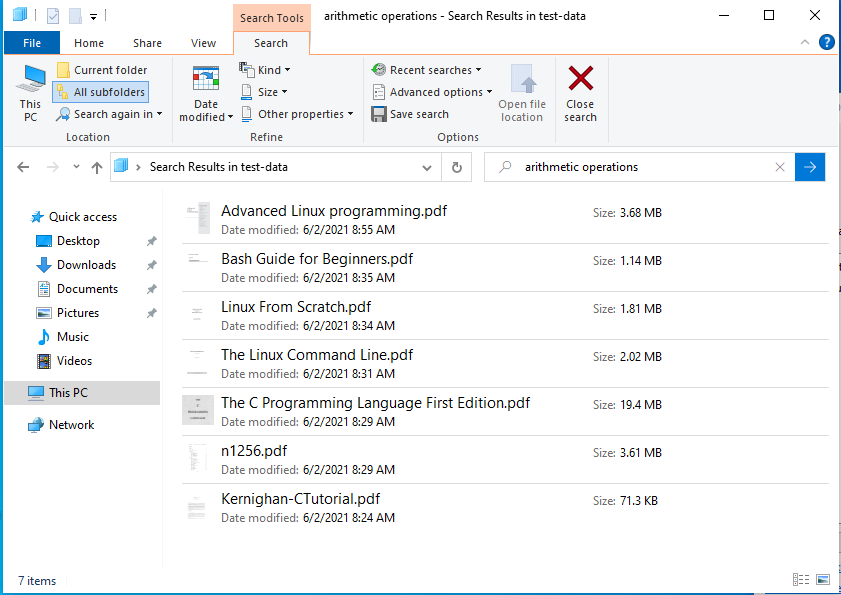
Finally in the explorer bar, just type in the search terms, and all the indexed location, will be searched for file properties and content. Additionally, under Advanced options, you can select File content for non-indexed locations, to allow searching for file contents in non-indexed locations.
Boolean operators, such AND, OR, NOT, seem to work, wildcards, and NEAR, do not seem to work. Documentation for performing content search, is scarce, but some form of documentation can be found here .
Lookeen
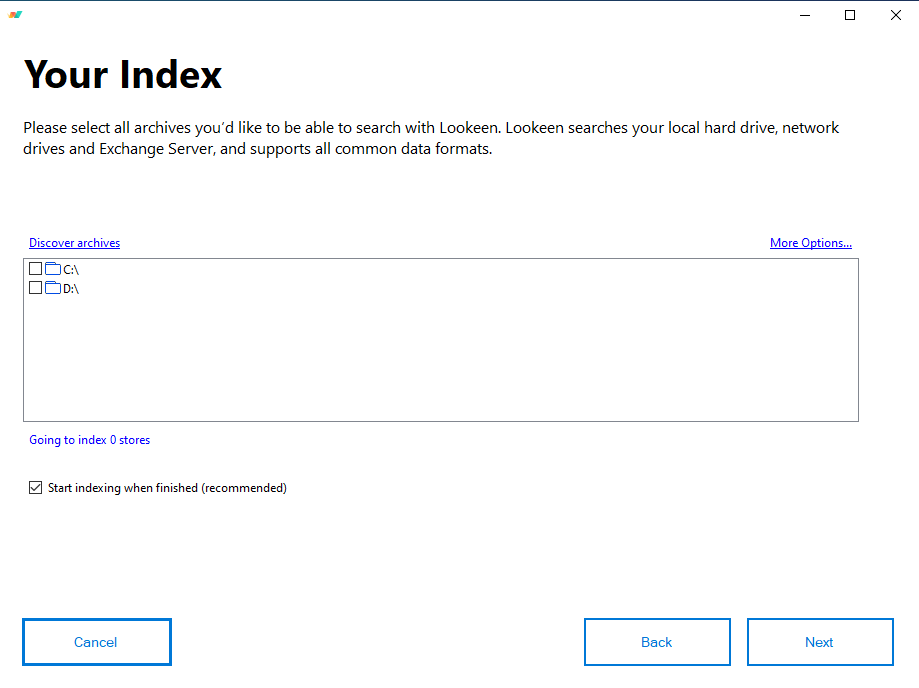
This one has only a paid product, which offers a 14 days trial. Once installation is done, some screens with simple explanation about the program are shown, after that you can select the drives, that you wish to index.
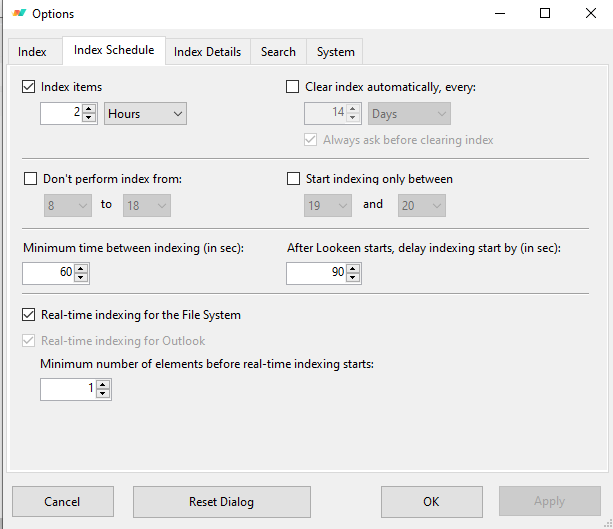
Once this is done, indexing can be started manually. Indexing can be configured to run at a given schedule, and what is to be indexed can also be configured. Index can be paused, if so, it is restarted after an hour.
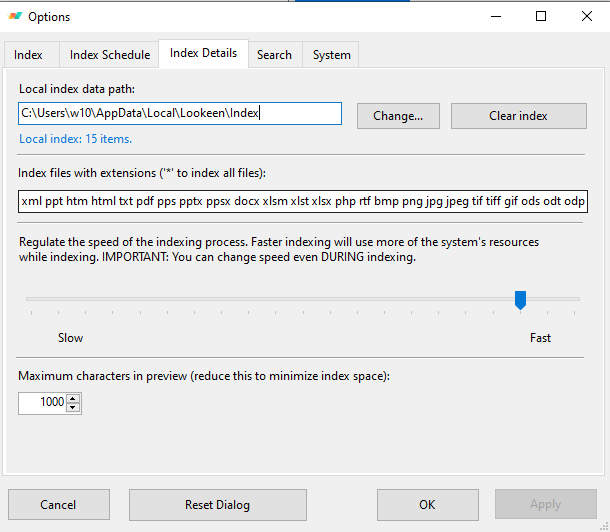
Lookeen supports indexing pdf, word, excel, PowerPoint, and text files, but it seems that this product, has a focus trend for searching outlook.
Lookeen has a query language similar to Lucene . Basically if no operators are used, this is as using AND . Instead of the Boolean NOT operator, Lookeen defines - , for example A -B , matches A but not B . Instead of the NEAR operator, you can use ~ , as in "pointer declaration"~3 , which means that pointer and declaration must be within 3 words from one another. The interrogation mark, ? , can also be used to match any one character, and an asterisk, * , can be used to match any number of characters.
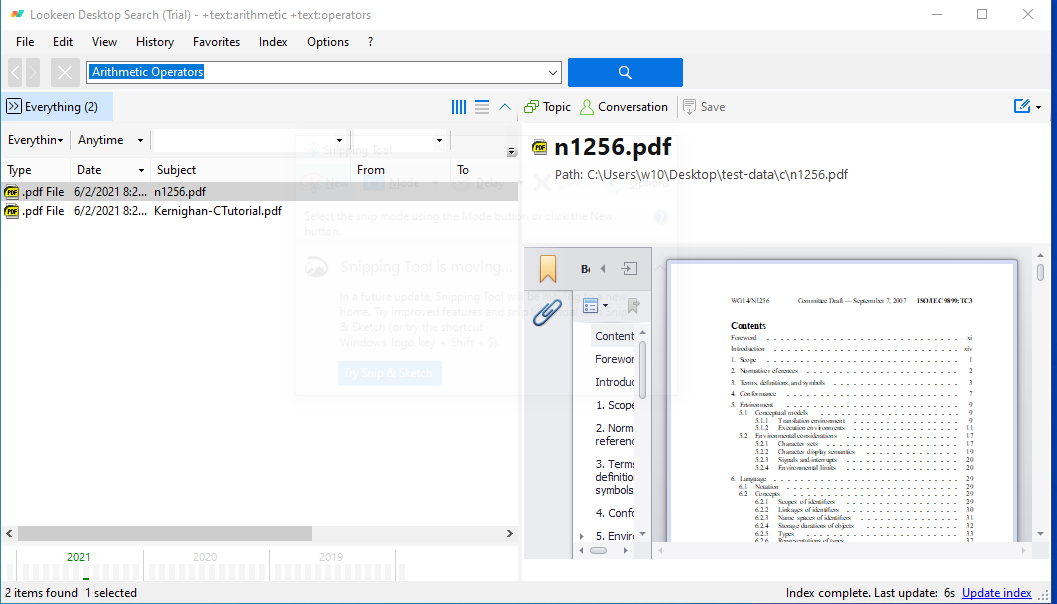
The preview pane does not highlight the found words, or on which page in a document, that a match was found.
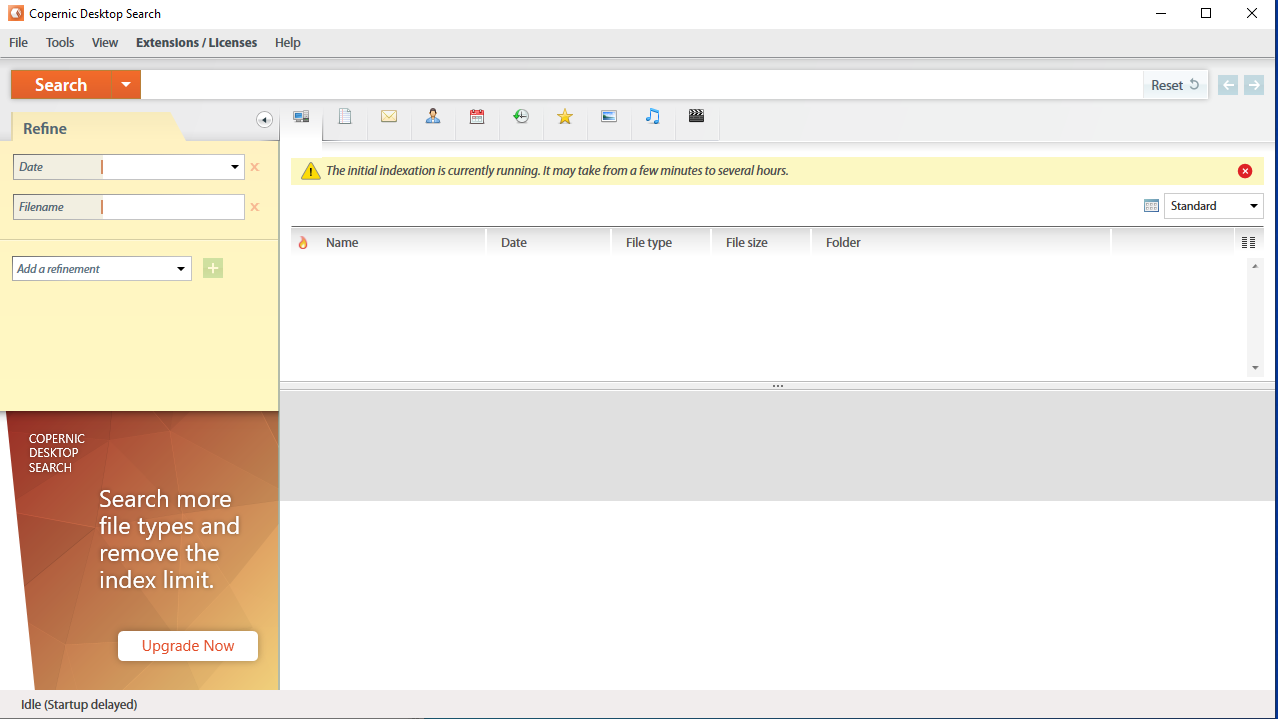
This one has multiple editions, which differences can be found here . But basically, there is a free edition, which is severely limited, for example it cannot search pdf or word or excel files, and there are paid editions, which prices range from 15 to 55$, the advanced edition is the full edition, so it has all the program features. You can get a free 30 days trial for the full edition.
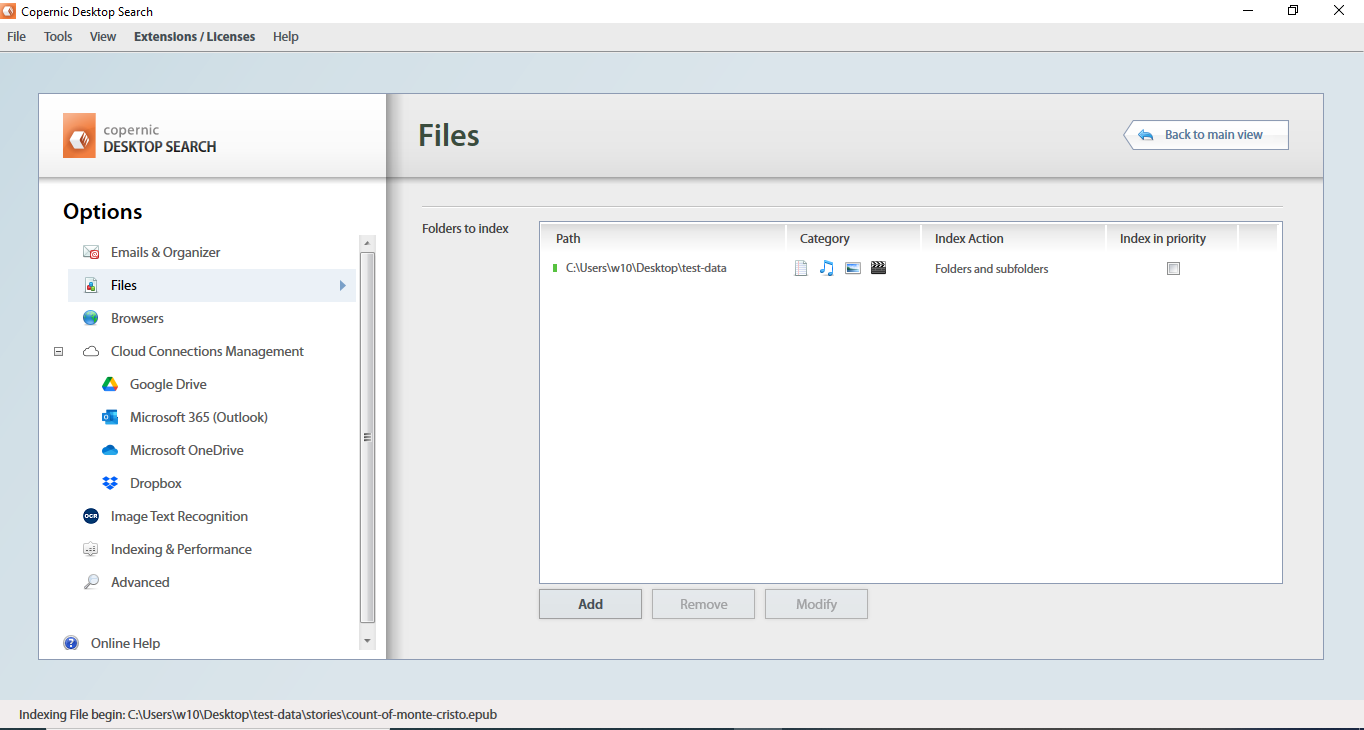
Copernic takes a sizable amount of ram to operate, and it does consume CPU. It automatically adds the hard drives as to be indexed, and indexes them, which can be a good or bad thing, depending on the user, some do prefer to have the ability to choose, the locations to be indexed.
You can after the program has started, configure the locations that you want to index. Copernic claims to be able to index around 119 file types, which list can be found here .
Basically, the full version supports searching the content of PowerPoint, excel, word, pdf, EPUB, CHM, and text files. It also supports the indexing of meta properties, for certain file types, such as for music you can search by artist or album, it also claims to be able to perform OCR search.
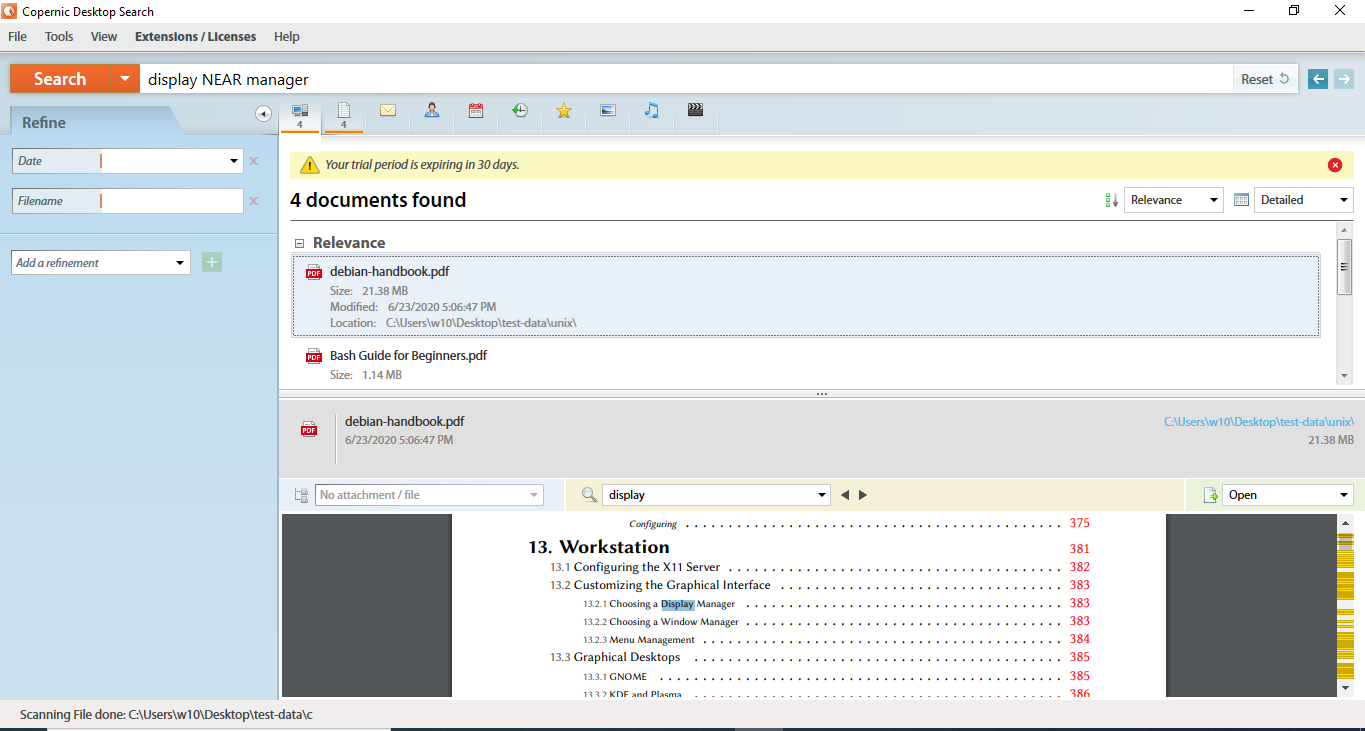
Boolean operatorsAND, NOT, OR, NEAR, EXCEPT can be used while performing search, parenthesis can also be used for grouping, and quotation mark can be used for exact match.
There is what is called a detailed view, in which you can sort results by relevance or filename or … If you click on the found result, a preview pane is opened, but highlighting of the search terms does not work well, it seems Copernic when opening the found result, will only highlight the first keyword.
Wingrep and AstroGrep are like the Unix grep utility, which is about searching textual files, using regular expressions, and without the use of an index. So mainly these tools do not support PDF documents, or other documents which do not contain simple text. AstroGrep states that possibly in the future, it could support using iFilters.
There is additionally pdfgrep which you can install using WSL, and which allows searching PDF files using regular expression, and without the use of an index.
How to solve package org.apache.http does not exist ? When compiling a java file you might face an error of : error: package org.apache.http does not exist Just download the Apache HttpComponents , and select the appropriate version . For example the HttpClient 5.0.3 version , or the…
binary search algorithm in python , and php Binary search algorithm Binary search is used to find if a sorted iterable , that can be indexed , contains an element in O(nlog(n)). It is faster than a a sequential search , where we can check if an element…